| TOCHARIAN LANGUAGES
Tocharian B manuscript, c. 7th century AD Tocharian
(a. k. a. Agnean-Kuchean)
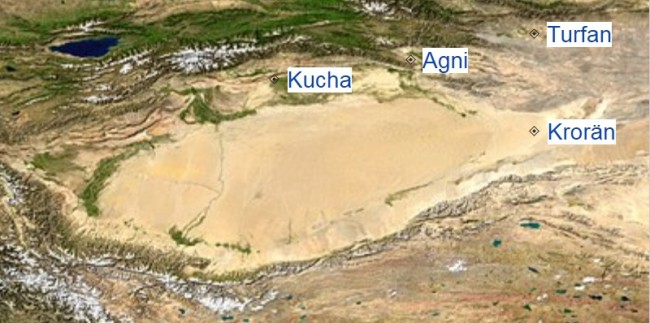
Native to : Agni, Kuch, Turfan and Krorän
Region : Tarim Basin
Ethnicity : Tocharians
Extinct : 9th century AD
Language
family : Indo-European
Early form : Proto-Tocharian
Dialects
:
Language codes :
ISO 639-3 :
Either
Linguist List
xto Tocharian A
txb Tocharian B
Glottolog : tokh1241
The Tocharian (sometimes Tokharian) languages, also known as Agnean-Kuchean or Kuchean-Agnean, are an extinct branch of the Indo-European language family. They are known from manuscripts dating from the 5th to the 8th century AD, which were found in oasis cities on the northern edge of the Tarim Basin (now part of Xinjiang in northwest China) and the Lop Desert. The discovery of this language family in the early 20th century contradicted the formerly prevalent idea of an east–west division of the Indo-European language family on the centum–satem isogloss, and prompted reinvigorated study of the family. Mistakenly identifying the authors with the Tokharoi people of ancient Bactria (Tokharistan), early authors called these languages "Tocharian". This naming has remained, although the names Agnean and Kuchean have been proposed as a replacement.
The documents record two closely related languages, called Tocharian A (also East Tocharian, Agnean or Turfanian) and Tocharian B (West Tocharian or Kuchean). The subject matter of the texts suggests that Tocharian A was more archaic and used as a Buddhist liturgical language, while Tocharian B was more actively spoken in the entire area from Turfan in the east to Tumshuq in the west. A body of loanwords and names found in Prakrit documents from the Lop Nor basin have been dubbed Tocharian C (Kroränian). A claimed find of ten Tocharian C texts written in Kharosthi script has been discredited.
The oldest extant manuscripts in Tocharian B are now dated to the 5th or even late 4th century AD, making Tocharian a language of Late Antiquity contemporary with Gothic, Classical Armenian and Primitive Irish.
Discovery and significance :
The geographical spread of Indo-European languages
Tocharian
languages A (blue), B (red) and C (green) in the Tarim Basin. Tarim
oasis towns are given as listed in the Book of Han (c. 2nd century
BC). The areas of the squares are proportional to population.
It soon became clear that these fragments were actually written in two distinct but related languages belonging to a hitherto unknown branch of Indo-European, now known as Tocharian :
•
Tocharian A (Agnean
or East Tocharian; natively arsi) of Qarašähär (ancient
Agni, Chinese Yanqi) and Turpan (ancient Turfan and Xoco), and
Prakrit documents from 3rd-century Krorän and Niya on the southeast edge of the Tarim Basin contain loanwords and names that appear to come from a closely related language, referred to as Tocharian C.
The discovery of Tocharian upset some theories about the relations of Indo-European languages and revitalized their study. In the 19th century, it was thought that the division between centum and satem languages was a simple west–east division, with centum languages in the west. The theory was undermined in the early 20th century by the discovery of Hittite, a centum language in a relatively eastern location, and Tocharian, which was a centum language despite being the easternmost branch. The result was a new hypothesis, following the wave model of Johannes Schmidt, suggesting that the satem isogloss represents a linguistic innovation in the central part of the Proto-Indo-European home range, and the centum languages along the eastern and the western peripheries did not undergo that change.
Most scholars reject Walter Bruno Henning's proposed link to Gutian, a language spoken on the Iranian plateau in the 22nd century BC and known only from personal names.
Tocharian probably died out after 840 when the Uyghurs, expelled from Mongolia by the Kyrgyz, moved into the Tarim Basin. The theory is supported by the discovery of translations of Tocharian texts into Uyghur.
Some modern Chinese words may ultimately derive from a Tocharian or related source, eg. Old Chinese *mjit (mì) "honey", from proto-Tocharian *met(e) (where *m is palatalized; cf. Tocharian B mit), cognate with English mead.
Names :
So-called "Tocharian donors" fresco, Qizil, Tarim Basin. These frescoes are associated with annotations in Tocharian and Sanskrit made by their painters. They were carbon dated to 432–538 CE. The style of the swordsmen is now considered to belong to the Hephthalites, from Tokharistan, who occupied the Tarim Basin from 480 to 560 CE, but spoke Bactrian, an Eastern Iranian language.
One of the painters, with a label in Tocharian: Citrakara Tutukasya "The Painter Tutuka". Cave of the Painters, Kizil Caves, circa 500 CE A colophon to a Buddhist manuscript in Old Turkish from 800 AD states that it was translated from Sanskrit via a twyry language. In 1907, Emil Sieg and Friedrich W. K. Müller guessed that this referred to the newly discovered language of the Turpan area. Sieg and Müller, reading this name as toxrï, connected it with the ethnonym Tócharoi (Ptolemy VI, 11, 6, 2nd century AD), itself taken from Indo-Iranian (cf. Old Persian tuxari-, Khotanese ttahvara, and Sanskrit tukhara), and proposed the name "Tocharian" (German Tocharisch). Ptolemy's Tócharoi are often associated by modern scholars with the Yuezhi of Chinese historical accounts, who founded the Kushan empire. It is now clear that these people actually spoke Bactrian, an Eastern Iranian language, rather than the language of the Tarim manuscripts, so the term "Tocharian" is considered a misnomer.
Nevertheless, it remains the standard term for the language of the Tarim Basin manuscripts.
In 1938, Walter Henning found the term "four twyry" used in early 9th-century manuscripts in Sogdian, Middle Iranian and Uighur. He argued that it referred to the region on the northeast edge of the Tarim, including Agni and Karakhoj but not Kuch. He thus inferred that the colophon referred to the Agnean language.
Although the term twyry or toxrï appears to be the Old Turkic name for the Tocharians, it is not found in Tocharian texts. The apparent self-designation arsi appears in Tocharian A texts. Tocharian B texts use the adjective kusiññe, derived from kusi or kuci, a name also known from Chinese and Turkic documents. The historian Bernard Sergent compounded these names to coin an alternative term Arsi-Kuci for the family, recently revised to Agni-Kuci, but this name has not achieved widespread usage.
Writing system :
Tocharian is documented in manuscript fragments, mostly from the 8th century (with a few earlier ones) that were written on palm leaves, wooden tablets and Chinese paper, preserved by the extremely dry climate of the Tarim Basin. Samples of the language have been discovered at sites in Kucha and Karasahr, including many mural inscriptions.
Most of attested Tocharian was written in the Tocharian alphabet, a derivative of the Brahmi alphabetic syllabary (abugida) also referred to as North Turkestan Brahmi or slanting Brahmi. However a smaller amount was written in the Manichaean script in which Manichaean texts were recorded. It soon became apparent that a large proportion of the manuscripts were translations of known Buddhist works in Sanskrit and some of them were even bilingual, facilitating decipherment of the new language. Besides the Buddhist and Manichaean religious texts, there were also monastery correspondence and accounts, commercial documents, caravan permits, medical and magical texts, and one love poem.
In 1998, Chinese linguist Ji Xianlin published a translation and analysis of fragments of a Tocharian Maitreyasamiti-Nataka discovered in 1974 in Yanqi.
Tocharian A and B :
Cities
of the ancient Tarim Basin relevant for Tocharian. Tocharian A is
found in Agni and Turfan, Tocharian B is found in both of these,
as well as Kucha. Loanwords into Prakrit from another variety of
Tocharian are found in Krorän.
Tocharian A is found only in the eastern part of the Tocharian-speaking area, and all extant texts are of a religious nature. Tocharian B, however, is found throughout the range and in both religious and secular texts. As a result, it has been suggested that Tocharian A was a liturgical language, no longer spoken natively, while Tocharian B was the spoken language of the entire area. On the other hand, it is possible that the lack of a secular corpus in Tocharian A is simply an accident, due to the smaller distribution of the language and the fragmentary preservation of Tocharian texts in general.[citation needed]
The hypothesized relationship of Tocharian A and B as liturgical and spoken forms, respectively, is sometimes compared with the relationship between Latin and the modern Romance languages, or Classical Chinese and Mandarin. However, in both of these latter cases the liturgical language is the linguistic ancestor of the spoken language, whereas no such relationship holds between Tocharian A and B. In fact, from a phonological perspective Tocharian B is significantly more conservative than Tocharian A, and serves as the primary source for reconstructing Proto-Tocharian. Only Tocharian B preserves the following Proto-Tocharian features: stress distinctions, final vowels, diphthongs, and o vs. e distinction. In turn, the loss of final vowels in Tocharian A has led to the loss of certain Proto-Tocharian categories still found in Tocharian B, e.g. the vocative case and some of the noun, verb and adjective declensional classes.
In their declensional and conjugational endings, the two languages innovated in divergent ways, with neither clearly simpler than the other. For example, both languages show significant innovations in the present active indicative endings but in radically different ways, so that only the second-person singular ending is directly cognate between the two languages, and in most cases neither variant is directly cognate with the corresponding Proto-Indo-European (PIE) form. The agglutinative secondary case endings in the two languages likewise stem from different sources, showing parallel development of the secondary case system after the Proto-Tocharian period. Likewise, some of the verb classes show independent origins, e.g. the class II preterite, which uses reduplication in Tocharian A (possibly from the reduplicated aorist) but long PIE e in Tocharian B (possibly from the long-vowel perfect found in Latin legi, feci, etc.).
Tocharian B shows an internal chronological development; three linguistic stages have been detected. The oldest stage is attested only in Kucha. There are also the middle ('classical'), and the late stage.
Tocharian
C :
In 2018, ten texts written in the Kharosthi alphabet from Loulan were published and analyzed in the posthumous papers of Tocharologist Klaus T. Schmidt as being written in Tocharian C. Schmidt suggested that the language was closer to Tocharian B than to Tocharian A. On September 15 and 16, 2019, a group of linguists led by Georges Pinault and Michaël Peyrot met in Leiden to examine Schmidt's transcriptions and the original texts, and concluded they had all been transcribed entirely incorrectly. Their conclusions appear to have discredited Schmidt's Tocharian C claims.
Phonology
:
Vowels :
Tocharian A and Tocharian B have the same set of vowels, but they often do not correspond to each other. For example, the sound a did not occur in Proto-Tocharian. Tocharian B a is derived from former stressed ä or unstressed a (reflected unchanged in Tocharian A), while Tocharian A a stems from Proto-Tocharian (reflected as /e/ and /o/ in Tocharian B), and Tocharian A e and o stem largely from monophthongization of former diphthongs (still present in Tocharian B).
Diphthongs
:
Consonants
:
Continued
...
1.
/n/ is transcribed by two different letters in the Tocharian alphabet
depending on position. Based on the corresponding letters in Sanskrit,
these are transcribed (word-finally, including before certain clitics)
and n (elsewhere), but m represents /n/, not /m/.
Tocharian
has completely re-worked the nominal declension system of Proto-Indo-European.
The only cases inherited from the proto-language are nominative,
genitive, accusative, and (in Tocharian B only) vocative; in Tocharian
the old accusative is known as the oblique case. In addition to
these primary cases, however, each Tocharian language has six cases
formed by the addition of an invariant suffix to the oblique case
— although the set of six cases is not the same in each language,
and the suffixes are largely non-cognate. For example, the Tocharian
word yakwe (Toch B), yuk (Toch A) "horse" < PIE *ekwos
is declined as follows :
The Tocharian A instrumental case rarely occurs with humans.
When referring to humans, the oblique singular of most adjectives and of some nouns is marked in both varieties by an ending -(a)m, which also appears in the secondary cases. An example is enkwe (Toch B), onk (Toch A) "man", which belongs to the same declension as above, but has oblique singular enkwem (Toch B), onkam (Toch A), and corresponding oblique stems enkwem- (Toch B), onkn- (Toch A) for the secondary cases. This is thought to stem from the generalization of n-stem adjectives as an indication of determinative semantics, seen most prominently in the weak adjective declension in the Germanic languages (where it cooccurs with definite articles and determiners), but also in Latin and Greek n-stem nouns (especially proper names) formed from adjectives, e.g. Latin Cato (genitive Catonis) literally "the sly one" [citation needed] < catus "sly", Greek Pláton literally "the broad-shouldered one" < platús "broad".
Verbs
:
In addition, most PIE sets of endings are found in some form in Tocharian (although with significant innovations), including thematic and athematic endings, primary (non-past) and secondary (past) endings, active and mediopassive endings, and perfect endings. Dual endings are still found, although they are rarely attested and generally restricted to the third person. The mediopassive still reflects the distinction between primary -r and secondary -i, effaced in most Indo-European languages. Both root and suffix ablaut is still well-represented, although again with significant innovations.
Categories
:
•
Mood : indicative,
subjunctive, optative, imperative.
Present
indicative :
I:
Athematic without suffix < PIE root athematic.
Subjunctive
:
In addition, four subjunctive classes differ from the corresponding indicative classes, two "special subjunctive" classes with differing suffixes and two "varying subjunctive" classes with root ablaut reflecting the PIE perfect.
Special subjunctives :
iv:
Thematic with suffix i < PIE -y-, with consistent palatalization
of final root consonant. Tocharian B only, rare.
i:
Athematic without suffix, with root ablaut reflecting PIE o-grade
in active singular, zero-grade elsewhere. Derived from PIE perfect.
I:
The most common class, with a suffix a < PIE H (i.e. roots ending
in a laryngeal, although widely extended to other roots). This class
shows root ablaut, with original e-grade (and palatalization of
the initial root consonant) in the active singular, contrasting
with zero-grade (and no palatalization) elsewhere.
Imperative
:
Classes i through v tend to co-occur with preterite classes I through V, although there are many exceptions. Class vi is not so much a coherent class as an "irregular" class with all verbs not fitting in other categories. The imperative classes tend to share the same suffix as the corresponding preterite (if any), but to have root vocalism that matches the vocalism of a verb's subjunctive. This includes the root ablaut of subjunctive classes i and v, which tend to co-occur with imperative class i.
Optative
and imperfect :
Endings
:
The present-tense endings are almost completely divergent between Tocharian A and B. The following shows the thematic endings, with their origin :
Thematic present active indicative endings
Continued
...
Continued
...
Comparison to other Indo-European languages :
Continued
...
Continued
...
Continued
...
Continued
...
In traditional Indo-European studies, no hypothesis of a closer genealogical relationship of the Tocharian languages has been widely accepted by linguists. However, lexicostatistical and glottochronological approaches suggest the Anatolian languages, including Hittite, might be the closest relatives of Tocharian. As an example, the same Proto-Indo-European root *h2wrg(h)- (but not a common suffixed formation) can be reconstructed to underlie the words for 'wheel': Tocharian A wärkänt, Tokharian B yerkwanto and Hittite hurkis.
Source :
https://en.wikipedia.org/wiki/ |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||



_Cave_of_the_Painters,_Kizil_Caves,_circa_500_CE.jpg)